

Wie vielleicht einige von euch wissen, faszinieren mich Technik und Geschichte des Teletexts, hierzulande eher bekannt als Videotext, schon seit langem. Die damals wie heute ingenieurstechnisch höchst clevere Mischung aus digitaler Codierung und analoger Fernsehübertragung, insbesondere die Art und Weise, wie das Signal aufgebaut ist und wie einfach es dadurch auf Hardware der damaligen Zeit decodiert werden kann, finde ich bis heute großartig. Auch wenn ich durchaus immer mal wieder meine Zweifel hatte, ob seine schiere Existenz heute noch gerechtfertigt ist, bin ich doch sehr dafür, ihn zu pflegen und gut zu behandeln, solange wir ihn noch haben. ;)
Wie begann sie also, meine „Teletext-Geschichte“? Da meine Großeltern bereits seit den späten 80er-Jahren einen Fernseher mit Videotext-Decoder hatten (im Gegensatz zu meinen Eltern) und ich dort regelmäßig den „Witz des Tages“ (im ARD/ZDF-Videotext auf Tafel 571…) lesen durfte, gehörte dieses Medium für mich von Kindesbeinen an dazu. Wie es genau funktionierte, verstand ich natürlich erst viel später.
Als dann irgendwann Level 2.5-Teletext aufkam und spätere Fernsehgeräte, mit denen ich in der Familie in Berührung kam, tatsächlich diesen Standard unterstützten (Wow! Plötzlich richtige Logos, wie beim ZDF, und eine ungeahnte Farbenvielfalt im Videotext!…), wollte ich irgendwann wirklich wissen, wie das alles funktioniert, und begann, mir im Internet – zum Glück wurde das damals gerade möglich – die entsprechenden Standards zusammenzusuchen und mich einzulesen.
Im Jahr 2011 habe ich mich dann in einem Blogbeitrag und einem zugehörigen, längeren Artikel mit den technischen Hintergründen des Standards beschäftigt und habe versucht, diesen in möglichst verständlichen Worten zu erklären.
Da ich mich in der Folgezeit selbst auch immer mehr mit (Retro-)Hardware beschäftigt habe, wurde mir seitdem mehr und mehr klar, mit welch einfachen Logikbauteilen eine Dekodierung eines Teletext-Signals möglich ist. Wie wenig „State“ ein solcher Decoder hat. Dass es letztlich nur ein paar Bytes RAM, ein paar (Schiebe)register, ein paar Logikbausteine, einen Character Generator mit CG-ROM und ein bisschen Videoelektronik braucht, um einen Teletext-Decoder zu realisieren. Theoretisch alles mit diskreten Bauteilen machbar (bis auf den Seiten-RAM und das CGROM vielleicht).
Irgendwann hatte ich seitdem immer Lust, so etwas selber – komplett diskret – nachzubauen. Allein, es fehlte mir die Zeit und die Muße. Später sah ich dann, dass das schon andere getan haben – in VHDL, was eine großartige Idee ist.
In meinem Beruf ergab sich dann irgendwann die Herausforderung, die Web-Darstellung des hr-texts, des Videotexts des Hessischen Rundfunks, technisch auf neue Beine zu stellen, wenn auch zunächst als vages Ziel, ohne konkreten Auftrag oder Deadline.
Meine Idee, einen eigenen Videotext-Decoder – zumindest Seiten-Decoder, ohne die Empfangs- und Auswahllogik, die ja beim Decodieren von fertigen, als Datei vorliegenden Seiten nicht nötig ist – zu schreiben, in dem Fall mit Ausgabe als HTML, nahm hierdurch neue Gestalt an, und ich programmierte „nebenher“ eine kleine Skriptsammlung in PHP, die genau das tat: ttxweb.
ttxweb kann Videotext-Daten aus einer Datei (momentan im EP1-Dateiformat, eine Anpassung an alle anderen Dateiformate, die Level 1.0/1.5-Teletext-Daten enthalten, ist aber sehr leicht machbar) lesen und in standardkonformes HTML wandeln, das in allen aktuellen Browsern aussieht wie eine „echte“ Teletextseite.
Die Besonderheit – zumindest für mich – daran ist, dass die Dekodierung genauso „stateless“ und ohne separaten „Framebuffer“ für die Displayattribute erfolgt, wie dies ein uralter Teletext-Decoder der allerersten Generation auch getan hätte.
Sprich: die Steuerzeichen werden im Zeitpunkt ihres Auftretens in Anweisungen für die HTML-Ausgabe übersetzt, anstatt dass für jede Zeichenzelle eine Speicherzelle für die Attribute (Vorder-/Hintergrundfarbe, Blinken etc.) vorgehalten würde, wie es z.B. bei einer VGA-Grafikkarte im Textmodus der Fall wäre.
Genau so arbeitet auch ein ursprünglicher Teletext-Decoder ohne Mehr-Seiten-Speicher: letztlich werden die Attribute wie Farbe, Blinken usw. in einfachen Registern vorgehalten und während jeder Rasterzeile während des Auslesens des Seitenspeichers und des CGROM in Echtzeit geändert, sobald im Seitenspeicher an der jeweiligen Spalte ein entsprechendes Steuerzeichen auftritt.
Mit dem Aufkommen von Level 1.5 (erweiterter Zeichensatz) bzw. Level 2.5 (erweiterte Farbpalette und dynamisch definierbare Zeichen) war ein solches Vorgehen dann nicht mehr möglich. Die erweiterten Zeichen bei Level 1.5 werden beispielsweise durch ein zusätzlich übertragenes Packet (X/26), also einer „unsichtbaren“ 26. Zeile, definiert, welche dem Decoder sagt, in welcher Zeile und welcher Spalte er ein Zeichen ersetzen soll. Hier ist definitiv Software nötig, um die entsprechenden Steuer-„Triplets“ zu durchlaufen.
Mein Decoder unterstützt – in auf die in europäischen Sprachen üblichen Sonderzeichen begrenztem Maße – Level 1.5, indem vor der Ausgabe die X/26-Triplets prozessiert und die betreffenden Zeichen durch die korrekten Unicode-HTML-Entitäten ersetzt werden.
Nun – wie ging die Geschichte aus? Ich habe das Ganze Open Source gemacht und auf GitHub gestellt und insbesondere der ARD und allen anderen öffentlich-rechtlichen Rundfunkanstalten ausdrücklich erlaubt, den Code zu verwenden (tatsächlich ist er auch in einem separaten Repository im ARD-internen GitLab eingecheckt, wo noch ein paar Konfigurations-Besonderheiten mitgepflegt werden, die Codebasis ist aber die gleiche). Die Lösung basiert auf zeitgemäßen Webtechnologien, ist mobil-tauglich bzw. responsiv, unterstützt Updates in Echtzeit via XHR, zeigt alle denkbaren Textattribute (inkl. doppelter Höhe/Breite/Größe und Blinken) an, unterstützt, wie gesagt, Level 1.5-Zeichen (auch das „gefürchtete“ @-Zeichen in allen möglichen Codiervarianten) und liest EP1-Dateien sowohl ohne als auch mit X/26-Erweiterungen aus, letztere in mehreren Geschmacksrichtungen (Softel Flair und Softel TAP).
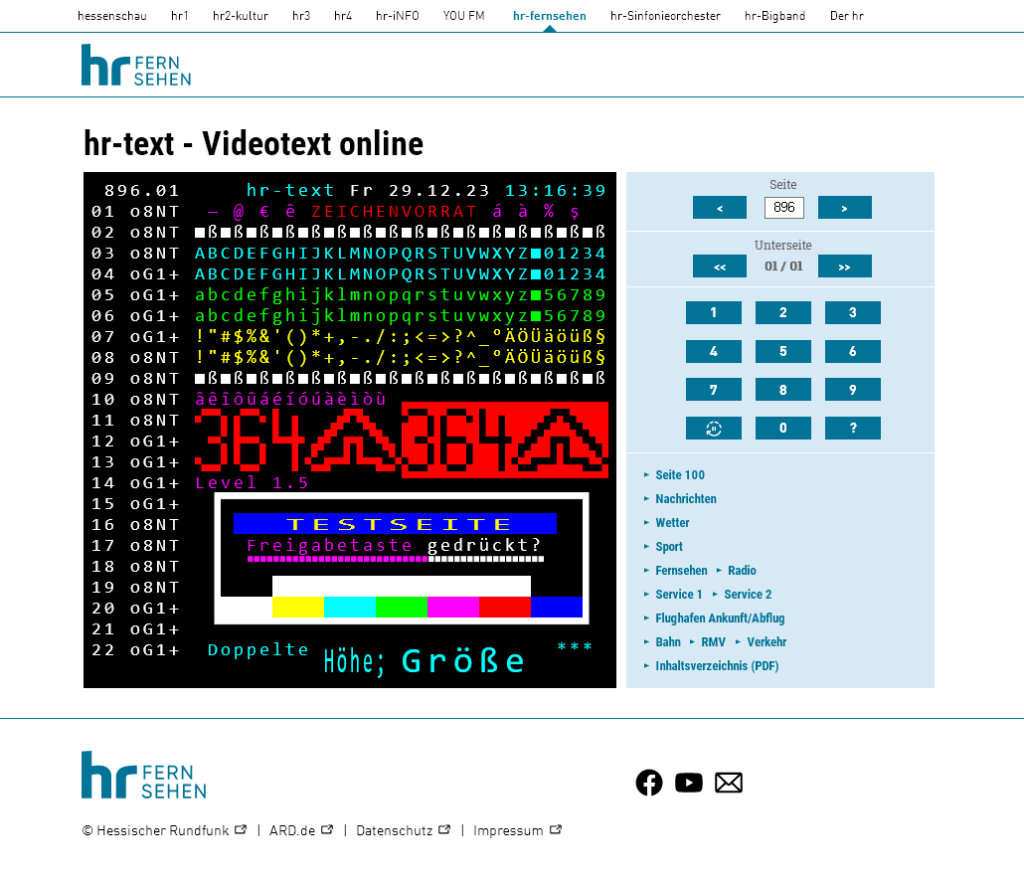
Als erster Sender der ARD nutzt der Hessische Rundfunk nun die Lösung für den hr-text – und spart damit jedes Jahr bares Geld, da nicht mehr auf einen externen Dienstleister für die Web-Darstellung zurückgegriffen werden muss. Das kommt allen Beitragszahlenden zugute. Die neue Lösung läuft auf einem schlanken Webserver (mehr braucht’s ja nicht) als VM in der „ARD-Cloud“ und kann von allen gern hier bewundert werden:
https://hr-text.hr-fernsehen.de
Und ja, ich geb’s zu: ein bisschen stolz bin ich darauf schon… ;-)
Falls irgendwo Interesse an einer Implementierung „in the wild“ bestehen sollte, zögert nicht, mich zu kontaktieren, falls es Fragen zum Deployment geben sollte.
Liebe Grüße und einen guten Rutsch,
Euer Fabian