Wie vielleicht einige von euch wissen, faszinieren mich Technik und Geschichte des Teletexts, hierzulande eher bekannt als Videotext, schon seit langem. Die damals wie heute ingenieurstechnisch höchst clevere Mischung aus digitaler Codierung und analoger Fernsehübertragung, insbesondere die Art und Weise, wie das Signal aufgebaut ist und wie einfach es dadurch auf Hardware der damaligen Zeit decodiert werden kann, finde ich bis heute großartig. Auch wenn ich durchaus immer mal wieder meine Zweifel hatte, ob seine schiere Existenz heute noch gerechtfertigt ist, bin ich doch sehr dafür, ihn zu pflegen und gut zu behandeln, solange wir ihn noch haben. ;)
Wie begann sie also, meine „Teletext-Geschichte“? Da meine Großeltern bereits seit den späten 80er-Jahren einen Fernseher mit Videotext-Decoder hatten (im Gegensatz zu meinen Eltern) und ich dort regelmäßig den „Witz des Tages“ (im ARD/ZDF-Videotext auf Tafel 571…) lesen durfte, gehörte dieses Medium für mich von Kindesbeinen an dazu. Wie es genau funktionierte, verstand ich natürlich erst viel später.
Als dann irgendwann Level 2.5-Teletext aufkam und spätere Fernsehgeräte, mit denen ich in der Familie in Berührung kam, tatsächlich diesen Standard unterstützten (Wow! Plötzlich richtige Logos, wie beim ZDF, und eine ungeahnte Farbenvielfalt im Videotext!…), wollte ich irgendwann wirklich wissen, wie das alles funktioniert, und begann, mir im Internet – zum Glück wurde das damals gerade möglich – die entsprechenden Standards zusammenzusuchen und mich einzulesen.
Im Jahr 2011 habe ich mich dann in einem Blogbeitrag und einem zugehörigen, längeren Artikel mit den technischen Hintergründen des Standards beschäftigt und habe versucht, diesen in möglichst verständlichen Worten zu erklären.
Da ich mich in der Folgezeit selbst auch immer mehr mit (Retro-)Hardware beschäftigt habe, wurde mir seitdem mehr und mehr klar, mit welch einfachen Logikbauteilen eine Dekodierung eines Teletext-Signals möglich ist. Wie wenig „State“ ein solcher Decoder hat. Dass es letztlich nur ein paar Bytes RAM, ein paar (Schiebe)register, ein paar Logikbausteine, einen Character Generator mit CG-ROM und ein bisschen Videoelektronik braucht, um einen Teletext-Decoder zu realisieren. Theoretisch alles mit diskreten Bauteilen machbar (bis auf den Seiten-RAM und das CGROM vielleicht).
Irgendwann hatte ich seitdem immer Lust, so etwas selber – komplett diskret – nachzubauen. Allein, es fehlte mir die Zeit und die Muße. Später sah ich dann, dass das schon andere getan haben – in VHDL, was eine großartige Idee ist.
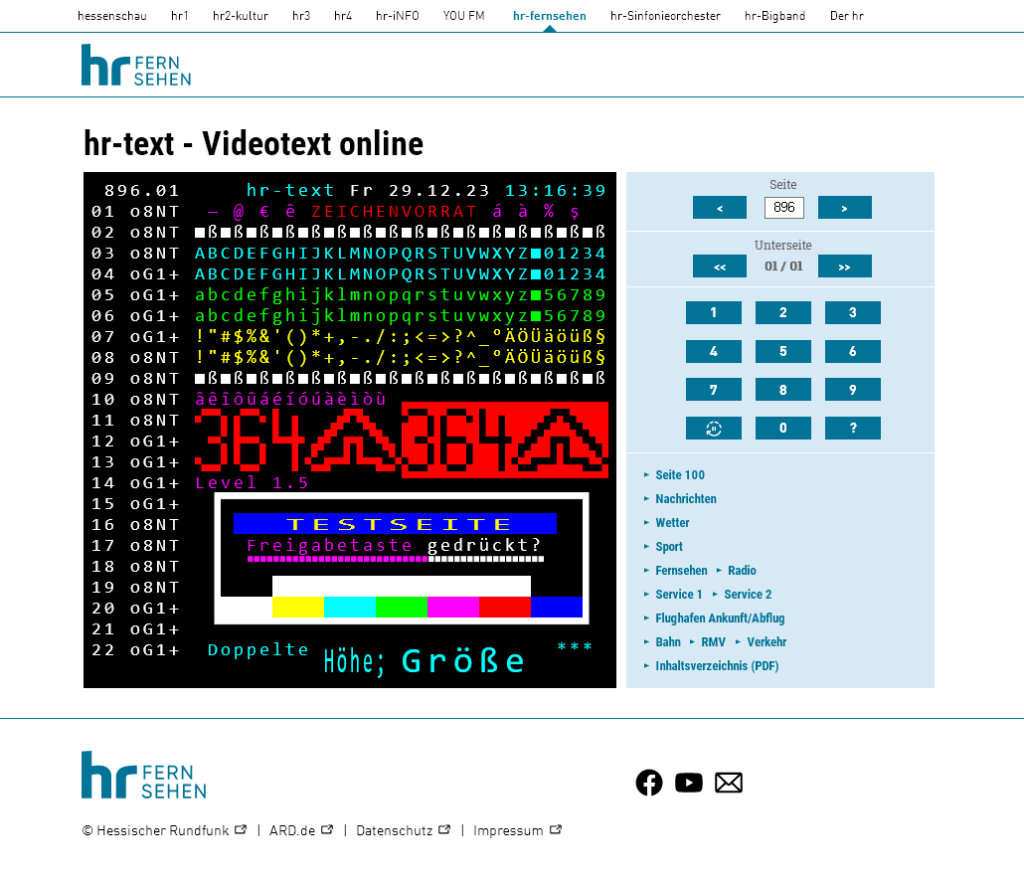
In meinem Beruf ergab sich dann irgendwann die Herausforderung, die Web-Darstellung des hr-texts, des Videotexts des Hessischen Rundfunks, technisch auf neue Beine zu stellen, wenn auch zunächst als vages Ziel, ohne konkreten Auftrag oder Deadline.
Meine Idee, einen eigenen Videotext-Decoder – zumindest Seiten-Decoder, ohne die Empfangs- und Auswahllogik, die ja beim Decodieren von fertigen, als Datei vorliegenden Seiten nicht nötig ist – zu schreiben, in dem Fall mit Ausgabe als HTML, nahm hierdurch neue Gestalt an, und ich programmierte „nebenher“ eine kleine Skriptsammlung in PHP, die genau das tat: ttxweb.
ttxweb kann Videotext-Daten aus einer Datei (momentan im EP1-Dateiformat, eine Anpassung an alle anderen Dateiformate, die Level 1.0/1.5-Teletext-Daten enthalten, ist aber sehr leicht machbar) lesen und in standardkonformes HTML wandeln, das in allen aktuellen Browsern aussieht wie eine „echte“ Teletextseite.
Die Besonderheit – zumindest für mich – daran ist, dass die Dekodierung genauso „stateless“ und ohne separaten „Framebuffer“ für die Displayattribute erfolgt, wie dies ein uralter Teletext-Decoder der allerersten Generation auch getan hätte.
Sprich: die Steuerzeichen werden im Zeitpunkt ihres Auftretens in Anweisungen für die HTML-Ausgabe übersetzt, anstatt dass für jede Zeichenzelle eine Speicherzelle für die Attribute (Vorder-/Hintergrundfarbe, Blinken etc.) vorgehalten würde, wie es z.B. bei einer VGA-Grafikkarte im Textmodus der Fall wäre.
Genau so arbeitet auch ein ursprünglicher Teletext-Decoder ohne Mehr-Seiten-Speicher: letztlich werden die Attribute wie Farbe, Blinken usw. in einfachen Registern vorgehalten und während jeder Rasterzeile während des Auslesens des Seitenspeichers und des CGROM in Echtzeit geändert, sobald im Seitenspeicher an der jeweiligen Spalte ein entsprechendes Steuerzeichen auftritt.
Mit dem Aufkommen von Level 1.5 (erweiterter Zeichensatz) bzw. Level 2.5 (erweiterte Farbpalette und dynamisch definierbare Zeichen) war ein solches Vorgehen dann nicht mehr möglich. Die erweiterten Zeichen bei Level 1.5 werden beispielsweise durch ein zusätzlich übertragenes Packet (X/26), also einer „unsichtbaren“ 26. Zeile, definiert, welche dem Decoder sagt, in welcher Zeile und welcher Spalte er ein Zeichen ersetzen soll. Hier ist definitiv Software nötig, um die entsprechenden Steuer-„Triplets“ zu durchlaufen.
Mein Decoder unterstützt – in auf die in europäischen Sprachen üblichen Sonderzeichen begrenztem Maße – Level 1.5, indem vor der Ausgabe die X/26-Triplets prozessiert und die betreffenden Zeichen durch die korrekten Unicode-HTML-Entitäten ersetzt werden.
Nun – wie ging die Geschichte aus? Ich habe das Ganze Open Source gemacht und auf GitHub gestellt und insbesondere der ARD und allen anderen öffentlich-rechtlichen Rundfunkanstalten ausdrücklich erlaubt, den Code zu verwenden (tatsächlich ist er auch in einem separaten Repository im ARD-internen GitLab eingecheckt, wo noch ein paar Konfigurations-Besonderheiten mitgepflegt werden, die Codebasis ist aber die gleiche). Die Lösung basiert auf zeitgemäßen Webtechnologien, ist mobil-tauglich bzw. responsiv, unterstützt Updates in Echtzeit via XHR, zeigt alle denkbaren Textattribute (inkl. doppelter Höhe/Breite/Größe und Blinken) an, unterstützt, wie gesagt, Level 1.5-Zeichen (auch das „gefürchtete“ @-Zeichen in allen möglichen Codiervarianten) und liest EP1-Dateien sowohl ohne als auch mit X/26-Erweiterungen aus, letztere in mehreren Geschmacksrichtungen (Softel Flair und Softel TAP).
Als erster Sender der ARD nutzt der Hessische Rundfunk nun die Lösung für den hr-text – und spart damit jedes Jahr bares Geld, da nicht mehr auf einen externen Dienstleister für die Web-Darstellung zurückgegriffen werden muss. Das kommt allen Beitragszahlenden zugute. Die neue Lösung läuft auf einem schlanken Webserver (mehr braucht’s ja nicht) als VM in der „ARD-Cloud“ und kann von allen gern hier bewundert werden:
Und ja, ich geb’s zu: ein bisschen stolz bin ich darauf schon… ;-)
Falls irgendwo Interesse an einer Implementierung „in the wild“ bestehen sollte, zögert nicht, mich zu kontaktieren, falls es Fragen zum Deployment geben sollte.
Über einen Sender, der meine Kindheit prägte, und über sein Design. Und über ein Buch darüber. Eine sehr persönliche Buchrezension mit ein paar Exkursen.
Dass ich vor einigen Monaten zum ersten Mal Werbung für das Buch „ZDF TV+Design“ in meine Instagram-Timeline gespült bekam, war wieder mal so einer der Fälle, wo man denkt, dass Microtargeting verdammt gut funktioniert und die Algorithmen wirklich gruselig genau wissen, wofür man sich interessiert…
Denn ja, es interessierte mich sehr! Ich, Kind der 80er, in Mainz und in einem ZDF-Mitarbeiter-Haushalt aufgewachsen, empfand mit dem ZDF und insbesondere seiner Ästhetik schon immer eine ganz besondere Verbindung. Ich muss wohl einige Male sehr anerkennende, „Haben-Wollen“ signalisierende Laute von mir gegeben und über das Buch gesprochen haben, und weil ich eine so aufmerksame Frau habe, bekam ich das Buch schließlich zum Geburtstag geschenkt. Wie von Geisterhand allerdings von meinen Eltern (man könnte meinen, meine Frau mag ihre Schwiegereltern sehr, so oft, wie die miteinander reden!) ;-)
Jedenfalls habe ich mich riesig darüber gefreut und natürlich sofort begonnen, das Werk minutiös zu degustieren. Eines direkt vorab: es lohnt sich auf allen Ebenen, ich empfehle das Buch uneingeschränkt und mit großer Freude weiter an alle, die sich für Design und Typographie, für Gebrauchsgrafik und Corporate Identity interessieren und/oder irgendetwas mit dem ZDF und seiner Geschichte verbinden.
„A5/11“
Nun aber zum Buch selbst. Es ist das elfte Buch der von Jens Müller herausgegebenen Reihe „A5“, die sich mit wichtigen Themen und Persönlichkeiten aus der Geschichte des internationalen Grafikdesigns beschäftigt und sich selbst als fortlaufend wachsendes Archiv versteht. Die Reihe, die in Kooperation mit dem Fachbereich Design an der Hochschule Düsseldorf sowie dem Fachbereich Design der Fachhochschule Dortmund entsteht, begann bei Lars Müller Publishers und wird mittlerweile beim Verlag OPTIK BOOKS fortgeführt.
Das Cover von A5/11: ZDF TV+Design (Quelle: OPTIK BOOKS)
Der Band „A5/11: ZDF TV+Design“ ist der erste und einzige aus der Reihe, den ich besitze, deshalb kann ich auf Reihe an sich gar nicht weiter eingehen und betrachte das Buch völlig für sich. Um es vorab zu sagen: ich finde es absolut lohnenswert, hochinteressant, schön gestaltet und mit vielen Beispielen sehr anschaulich.
Was ich beeindruckend fand, war, dass wirklich alle Ären des ZDF-Designs sehr umfassend besprochen und mit Bildern illustriert werden. Ich selbst habe als Kind noch die Ära miterlebt, in der Otl Aichers „ZDF“-Schriftzug in der charakteristischen, abgerundeten Schrift das Design prägte und quasi einziges verbindendes Element war. Insbesondere die späteren „Erweiterungen“ dieses Schriftzuges mit abgerundeten 3D-Flächen in Glas-Optik sind mir prägend in Erinnerung geblieben.
Aber auch das danach folgende ZDF-„Auge“ ist mir immer noch präsent – das Buch enthält auch dessen Entstehungsgeschichte und Erklärung des Designers, sodass ich das Signet erst heute wirklich verstanden habe (16 Bundesländer schieben sich als „Scheiben“ übereinander, formen die Kugel, die für die Weltkugel steht, der äußere Kreis ist das Publikum und der asymmetrisch versetzte Kreis soll als verbindendes Element die Rundfunkwellen symbolisieren) – clever, aber doch recht abstrakt und komplex und nicht unbedingt sofort etwas, bei dem man an „Zweites Deutsches Fernsehen“ denkt.
Deshalb war 2001 ja das neue Signet mit der 2 als Z so treffend, so unverwechselbar und eindeutig, dass es bis heute Bestand hat und hoffentlich auch lange noch bleibt. Ich finde es zeitlos und sehr gelungen.
Meine eigenen Erfahrungen mit dem ZDF-Design
All dies, und eben auch alle Evolutionsschritte dazwischen, stellt das Buch in Text und Bild echt toll dar, natürlich insbesondere für alle, die „dabei“ waren und sich sowieso schon immer dafür interessiert haben (und sich deshalb auch noch lebhaft selbst an die verschiedenen Design-Elemente erinnern). So zum Beispiel auch die Design-Epoche mit den verschiedenen bunten „Farbwelten“ für die verschiedenen Genres, bei dem das Augen-Signet als abstrakt „waberndes“ 3D-Elemnet in den Hintergrund trat und der Schriftzug „Das ZDF“ die Marke repräsentierte. Fand ich damals auch gut. Natürlich war der Schriftzug immer noch in der Otl-Aicher-Schrift gehalten. Übrigens auch etwas, das ich generell sehr zu schätzen weiß: das mutigste Redesign ist immer das, das sich traut, auch an Altem festzuhalten und es selbstbewusst für sich stehen zu lassen.
Und über Jahrzehnte hinweg – bis zur Einführung des heutigen Logos – war das ZDF-Design vor allem durch das Festhalten an dieser charakteristischen Schriftart geprägt. Selbst in dediziert neu gestalteten On-Air-Designs – wie beispielsweise dem heutzutage leider ziemlich in Vergessenheit geratenen „heute“-Design von 1998 und den daran angelehnten Ablegern wie dem Mittagsmagazin und auch dem Sport-Design aus dieser Epoche. Die Sendungstitel waren in – teils grafisch bearbeiteten, z.B. mit „angeschnittenen“ Ecken dargestellten – Typen der Otl-Aicher-Schrift gehalten, während Schrift-Inserts bereits in einer Swiss/Helvetica-ähnlichen Schrift, vor allem im Kursivschnitt, gehalten waren. Dieses Nachrichtendesign von 1998, in grün-blau gehalten, mit der Weltkugel als zentralem Gestaltungsmerkmal, die mit dem Kugel-und-Kreise-Signet als Animationselement spielt, verschiedene Farbakzente für die Sendungen „heute“ (blau), „heute journal“ (orange), „heute mittag“ (gelb) usw. einführt, und eben diese Mischung aus alter Schrift und neuen Elementen nutzt war für mich eine der prägendsten Neuerungen in der deutschen TV-Landschaft der späten 90er-Jahre.
Screenshot „heute“-Opener ab 1998. Der „heute“-Schriftzug ist in einer kursiv abgewandelten Variante der ursprünglichen Otl-Aicher-Rundschrift gestaltet (Quelle: ZDF, eigene Aufnahme)
Screenshot „heute journal“-Opener ab 1998. Der Zusatz „Journal“ führt den sendungsspezifischen orangenen Akzentbalken; der Text JOURNAL ist in Swiss oder einer ähnlichen Type gesetzt (Quelle: ZDF, eigene Aufnahme)
Ich erinnere mich noch genau, wie ich auf die erste Sendung aus der neuen Studio-Deko hingefiebert und diese dann sogar unterwegs – gemeinsam mit meinem Vater war ich auf einem Kurztrip nach Paderborn ins Heinrich-Nixdorf-Museums-Forum – abends im Zimmer unserer Frühstückspension auf dem kleinen, transportablen LCD-Fernseher geschaut habe. (Side Note: diese Dinger waren damals zwar der totale High-Tech und „die Zukunft“, aber halt qualitativ grottenschlecht. Farben konnte man zwar erahnen, aber nur, wenn man sich exakt im richtigen Winkel zum Briefmarkengroßen Display befand… trotzdem war es ein Erlebnis).
Tja, bereits 2001 wurde dieses Design dann im Rahmen des großen ZDF-Logo-Redesigns wieder abgelöst – wenn auch die Studio-Deko in ihrer Struktur erhalten blieb und nur mit neuen Materialien, Grafiken und Folien überklebt wurde und der Tisch umgestaltet wurde – aber es wurde eine ganz neue Farbwelt daraus: warme Holztöne, und dann der wunderbare Kontrast aus dem dunklen Nachrichten-Weltkugel-Blau und dem frischen neuen ZDF-Logo-Orange. Ja, das 2001er-Design war definitiv edel und sehr, sehr schön. Es wurde etwas Gutes mit etwas anderem Guten abgelöst, das ist es, warum mich dieser Designwechsel damals wie heute immer noch nicht kaltlässt.
Das Blau-Orange-Spiel hat dann ja auch immerhin bis 2009 sehr gut funktioniert, und ich habe es von Anfang bis Ende geliebt. Aber – wie gesagt: ich fand von Beginn an, dass es zwar absolut das Richtige, aber nicht per se besser als das Vorgängerdesign war.
Was ich damit vor allem sagen will: das 1998er-heute-Design hat einfach, auch retrospektiv, nie die Aufmerksamkeit und Anerkennung gefunden, die es meiner Meinung nach verdient gehabt hätte. Aufmerksamkeit, die es auch deshalb verdient hat, weil es – meiner Information nach – vollständig „inhouse“ und mit eher kleinem Budget entstanden ist und eben noch mit den althergebrachten Elementen (Kreise-Signet, Rundschrift) arbeitete, diese aber mit Neuem (Farbwelt, Weltkugel) verband und so eine ganz unverwechselbare Designwelt schuf.
Aufmerksamkeit, die es aber deshalb nicht lange bekam, weil eben 2001 etwas kam, das so stimmig und ebenfalls gut war, dass man den Vorgänger schnell vergaß, was ihm aber absolut unrecht tut.
Und, was im Übrigen auch gerne vergessen wird: das Design von 1998 ist deshalb retrospektiv wichtig, weil es einen ganz neuen, orchestralen Nachrichten-Sound im deutschen Fernsehen etablierte, der auf symphonischen Samples basierte (das vorige heute-Signet war 80er-typisch komplett synthie-basiert – was natürlich auch cool war, und die Tagesschau mit ihren synthetischen Bläsern wirkte auch eher bieder). Das neue orchestrale Thema von 1998 ließ mir damals auch ziemlich die Kinnlade runterklappen, kannte man so etwas doch bisher eigentlich nur aus dem amerikanischen Fernsehen.
Erwähnenswert ist das auch deshalb, weil das Design von 2001 die Melodien und Themes nahezu vollständig übernahm, sie nur nochmals – zeittypisch – mit etwas mehr „Wumms“ versah. Bis auf eine Ausnahme: das „heute journal“-Thema wurde komplett ersetzt, sodass man sagen kann, dass die 1998er-Variante die letzte war, die die ikonische Journal-Melodie beinhaltete (daaa – di – daaa, da da da daaaa, ihr wisst schon…). Die Version von 2001 führte für das Journal ein neues Thema ein, das – wiederum – ebenfalls hervorragend und episch war, sodass auch hier gesagt werden kann: etwas sehr sehr Gutes wurde durch etwas anderes, sehr sehr Gutes ersetzt. Im Nachhinein kann man sagen: passt schon. Das erste Gute hätte nur vielleicht ein paar Jahre mehr auf dem Sender verdient gehabt…
Ich merke gerade, dass meine Rezension zum Buch eigentlich gerade selbst zur Designkritik des ZDF-Designs und insbesondere zur Schwärmerei für die „heute“-Ära 1998-2001 wird, aber das musste gerade sein, und Kritik an einem Designbuch und Kritik am Design, das es behandelt, geht wohl manchmal nur Hand in Hand. Wie bin ich überhaupt darauf gekommen? Ach ja, ich wollte hervorheben, dass Aichers Schrift selbst im Jahr 1998, ja im Grunde bis 2001, noch eine zentrale Rolle spielte. Wer sich im Übrigen intensiver für Otl Aichers Einfluss und seinen ursprünglichen Entwurf und dessen Präsentation interessiert, dem sei dieser – reich bebilderte – Artikel wärmstens ans Herz gelegt, der ebenfalls vom Herausgeber des Buches stammt.
Also weiter im Text: Es werden in Müllers Buch natürlich auch die neuesten Entwicklungsschritte, also auch auch das Redesign im virtuellen Nachrichtenstudio (2021) und die Einführung der neuen, an die Helvetica angelehnten, Hausschrift thematisiert.
Und wieder zum ZDF-Design selbst: Das mit der neuen Hausschrift – ein Schritt, den ich zwiegespalten sehe. Das neue News-Design gefällt mir, keine Frage, aber die Abkehr von Helvetica ist für mich immer ein Abschied mit weinendem Auge. Ich will nicht sagen, dass die Helvetica das Non-Plus-Ultra für alle Anwendungen ist, aber wenn ein Design einmal mit der Helvetica funktioniert, dann gibt es wenig, was über diesen „Peak Typography“ hinauswachsen kann. Daher ist das Beste, was ich der neuen Schrift abgewinnen kann, dass sie nur behutsam vom Helvetica-Look weggeht und natürlich die praktischen Vorteile einer Uniwidth-Schrift sowie eine optimierte Lesbarkeit (I vs. l usw.) besitzt. Aber leider ist genau der letzte Punkt auch der, der mich furchtbar an der neuen Schrift stört.
Denn es gibt nichts, was ich fürchterlicher finde, als serifenlose Schriften, die dann aber bei der „I“-Versalie doch Serifen haben. Das finde ich irgendwie… nicht richtig.
Nun ja, aber auch daran gewöhnt man sich auch, wie auch an die Tatsache, dass die Schrift in verschiedenen Schnitten mal den Bogen am kleinen „l“ hat und mal nicht.
Aber zurück zum Buch: all das wird wirklich schön dargestellt, nachgezeichnet und illustriert. Die grafische Gestaltung und die Produktion mit Poster-Umschlag wirken wertig. Die Interviews mit Zeitzeug*innen sind hochinteressant.
Es wird sogar ein kleiner Exkurs zum 3sat-Design gemacht, mit dem man an sich schon ein Buch füllen könnte (was auch so angemerkt wird – das lässt hoffen). Das 3sat-Design hat nämlich auch einige wirkliche Perlen zu bieten und Geschichten zu erzählen. Ich denke da vor allem an die damals designmäßig revolutionäre Sendung „kulturzeit„, die 1995 meines Erachtens Designmaßstäbe im deutschen Fernsehen setzte und auch, wenn ich mich recht entsinne, eine der ersten, wenn nicht die erste war, die im 16:9-PALplus-Verfahren ausgestrahlt wurde. Aber wie gesagt – das 3sat-Design wäre Stoff für einen eigenen Band…
Zum Schluss geht das Buch noch auf die verschiedenen Designs der ZDF-Spartenkanäle (ZDFinfo, ZDFneo, ZDFtheaterkanal bzw. ZDFkultur) und deren Geschichte ein – ein gelungener Abschluss, der das Buch insgesamt zu einer sehr runden Sache macht.
Lob und Kritik
Bei allem Lob muss ich am Schluss leider aber auch auf zwei Wermutstropfen zu sprechen kommen, die das Buch für mich keineswegs weniger lohnenswert machen, mich aber dennoch gestört haben. Zum einen muss man leider sagen, dass sich in den deutschen Texten ziemlich viele Rechtschreib- und Interpunktionsfehler eingeschlichen haben. Zu viele (und auch teils peinliche wie das „verpöhnte“ mit „h“ auf Seite 98) für meinen Geschmack. Keine Angst, ich bin niemand, der einen Text dafür verteufelt oder verurteilt, aber ich gehöre doch zu denen, die so etwas einfach beim Lesen stört und die sich fragen, ob man nicht mit etwas mehr Sorgfalt den einen oder anderen Fehlerteufel hätte vor dem Druck hätte austreiben können. Das Impressum erwähnt ein Lektorat für die englischsprachigen Texte, das lässt vermuten, dass man für die deutschen Texte auf einen dedizierten Lektor verzichtet hat – schade.
Und der zweite recht grobe Schnitzer, der bei einem Buch, das sich mit Design beschäftigt und von einem Team aus hauptberuflichen Designern und Forschenden zu diesem Thema herausgegeben wird, eigentlich nicht hätte passieren dürfen, ist folgender:
Soll die Handel Gothic EF darstellen – ist aber Courier New (Quelle: ZDF TV+Design, Hg.: Jens Müller, OPTIK BOOKS 2023, S. 110)
Ja, natürlich ist das nicht die Handel Gothic EF. Das ist Courier New, weil offensichtlich beim Einbetten der Schrift irgendwas schiefgelaufen ist und diese beim Druck dann durch die Courier New substituiert wurde. Etwas, das spätestens im Proof oder Andruck hätte auffallen müssen.
Wie das Beispiel hätte aussehen müssen, zeigt der folgende Ausschnitt aus dem ZDF-Styleguide, hier in der Ausgabe von 2008:
Beispiel Handel Gothic EF (Quelle: ZDF Basis-Styleguide 2008)
Auch das natürlich kein Weltuntergang, aber ein kleines Detail, das Detailverliebte (und wer, bitteschön, kauft sonst solche Bücher? ;-)) schon stören kann.
Falls irgendjemand von Verlag oder Herausgebenden das hier lesen sollte: bitte nicht als Mäkelei verstehen, ich habe mich über das Buch wirklich sehr gefreut und tue dies immer noch, wann immer ich es aus dem Regal nehme. Ich empfehle das Buch klar und uneingeschränkt weiter (an dieser Stelle übrigens – sicherheitshalber, auch wenn es selbstverständlich ist – der Hinweis: diese Buchrezension wie auch alle anderen Rezensionen in meinem Blog, sei es zu Medien oder Produkten, sind, trotz Namens- oder Markennennung und trotz Verlinkungen keine Werbung, völlig unabhängig aus intrinsischer Motivation entstanden und spiegeln einzig und allein meine persönliche Meinung wider!). Die Kritik, auch die obigen beiden Punkte, sind absolut konstruktiv gedacht – und als Verbesserungsvorschlag, sollte es eine zweite Print-Auflage geben.
Mehr gibt’s dann auch gar nicht mehr hinzuzufügen. Alles weitere muss man selbst lesen, und vor allem, angucken. Sollte man jedenfalls!
Das Buch gibt’s online und im gut sortierten Buchhandel, ihr findet das schon selbst – hier die ISBN: 978-3-9822542-4-1. Viel Freude!
Erst einmal allen, die das lesen, ein gutes, gesundes, glückliches neues Jahr!
Mit diesem kurzen Artikel möchte ich beginnen (nachdem ich dies früher irgendwo in den verwirrenden Tiefen meines Content-Management-Systems und auch nur seltenst tat), auch hier im Blog, „ganz vorne“, hin und wieder kurze Kritiken zu Medien aller Art, sei es Musik, Filme, Serien, Videos auf den diversen Plattformen, zu posten.
Den Anfang macht, weil aktuell geschaut und noch präsent, die ZDF-Produktion „Der Palast“, die die Geschichte des Berliner Friedrichstadt-Palastes, eingebettet in eine fiktionale Geschichte, erzählen soll. Lief im ZDF Anfang Januar 2022 als Dreiteiler, in der Mediathek ist das Machwerk in Form von sechs jeweils halb so langen Folgen abrufbar.
Ich schreibe hier keine vollständige Kritik, das haben schon andere sehr treffend getan, ich will nur ein paar Aspekte zur Sprache bringen, die mich persönlich ganz besonders gestört haben (die Liste an positiven Dingen ist leider tatsächlich kurz; mir fällt spontan kein Moment ein, an dem ich mich sonderlich gut unterhalten, überrascht, gespannt etc. gefühlt habe – einziger positiver Aspekt ist eigentlich die wirklich gute schauspielerische Leistung von Svenja Jung in ihrer Zwillingsrolle).
Also mache ich es kurz und schmerzlos: Die Produktion war in meinen Augen leider ziemlich erbärmlich, sowohl von Drehbuch und Handlung als auch von der Inszenierung und der Regie her. Nicht nur, dass weder Musik, Kostüme noch Choreografie auch nur im entferntesten an die späten 80er-Jahre erinnerten, es fuhren auch noch Autos herum, die erst ab 1994 gebaut wurden (z.B. ein viel zu neues Audi-Modell A4, intern 8D, als Taxi – sowas ist einfach so leicht vermeidbar, das ist der Job eines Requisiteurs, sowas zu checken); diverse gezeigte IKEA-Möbel gab es auch in Westdeutschland zu dieser Zeit noch nicht; die in einer Szene zu sehende Microsoft-Word-Version gab es ebenfalls erst ab 1991 (eindeutig Word 5.x, erkennbar an der Menüleiste oben und dem blauen Hintergrund; die 1989 aktuelle Version 4.x hatte das Menü noch unten), ganz abgesehen davon, dass der gezeigte PC-Monitor ausgeschaltet war (Power-LED war aus) und der Bildschirminhalt nur „reingeshopt“ wurde – da hätte man wenigstens auch die LED noch grün machen können…
Vom ZDF war man, wenn man z.B. die Ku’damm-Filme kennt, in Sachen „Historien-Doku-Dramedy“ oder wie auch immer man das nennen mag, doch sehr, sehr viel Besseres gewohnt.
Insgesamt meiner Ansicht nach eine ziemlich dahingehunzte Produktion. Man hat den Eindruck, das ZDF wollte einfach „nochmal sowas wie Adlon/KaDeWe“ machen, was quotentechnisch ja offensichtlich irgendwie funktioniert hatte.
Von dem Aspekt, dass die DDR-Geschichte hier vollkommen unzulässig verkürzt und in keinster Weise aufarbeitend dargestellt, sondern lediglich als Vehikel genutzt wurde und keine ernsthafte Beschäftigung seitens der Schaffenden mit dem politischen und gesellschaftlichen Geist der damaligen Zeit erkennbar ist, mal ganz abgesehen.
„Der einzige Fortschritt, den wir noch erreichen können, ist die Erkenntnis, dass wahrer Fortschritt nur in der Abkehr vom Zwang des ewigen Fortschritts liegen kann.“
… und dafür auf zwei „neuen“ DVB-S2-Transponder ihre Radioprogramme im AAC-LC-Codec auf. So weit, so technisch. Und so alt die Nachricht: bekannt ist das mittlerweile schon seit fast einem Jahr, der Probebetrieb der AAC-Sender läuft bereits seit Juni 2021 mehr oder weniger holprig. Nun wird es bald so weit sein: ab dem 14.12.2021 soll auf dem alten Transponder nur noch eine Hinweisschleife zu hören sein, Ende 2021 ist dann komplett Schluss mit Transponder 93.
Ich hab da so ein paar ganz persönliche Gedanken dazu, die ich an dieser Stelle gerne mit euch teilen mag. Hörfunk ist tatsächlich an sich nicht mein Metier, auch beruflich nicht, trotz der Tatsache, dass ich im Broadcast-Bereich tätig bin. So glaube ich, zumindest halbwegs einen Blick „von außen“ darauf zu haben, wenn ich sage, dass ich mit der Entscheidung der ARD doch arge Bauchschmerzen habe.
Grundsätzlich ist gegen den Umstieg auf neue Technik nichts einzuwenden, zumal wenn dadurch (wie es ja heißt) Kosten gespart werden können und eine technische „Zukunftssicherheit“ gewährleistet werden kann. Auf der anderen Seite bin ich ja auch ein ganz großer Fan der Sichtweise, bewährte Verfahren und Techniken nicht ohne Not abzuschalten oder ersetzen zu müssen, wenn diese ihren Zweck tadellos erfüllen. Ja, das Zitat zu Beginn dieses Posts stammt von mir selbst und zwar aus einem Blogbeitrag vom 24. März 2009.
Und genau in diesem Spagat findet sich wohl die ARD bei dieser Aktion wieder. Der alte Transponder war maximal kompatibel: Er war einer der letzten DVB-S-Transponder (nicht DVB-S2) – also auch mit wirklich altem Gerät, wie es zum Beispiel in alten, abbezahlten Kopfstellen von Gemeinschaftsantennenbetreibern seinen Dienst tut, oder auch Ommas altem SD-Satellitenreceiver, problemlos empfangbar. Der Codec war der für alle DVB-Geräte verpflichtend zu unterstützende, millionenfach implementierte und längst patent- und lizenzfrei dekodierbare „MPEG-1 Audio Layer II“-Codec.
Und da muss man jetzt einfach der Wahrheit ins Auge blicken, dass das neue Angebot auf den beiden neuen Transpondern im AAC-Codec nach wie vor mit vielen (selbst neueren) Receivern nicht oder nur in eingeschränkter Qualität nutzbar ist. Selbst wenn die ARD auf dieser Seite und in diversen Social-Media-Posts das Gegenteil behauptet und davon spricht, dass die meisten Geräte sich „schnell und einfach“ updaten ließen.
So klagen einige Hörer selbst bei eigentlich AAC-tauglichen Geräten über gelegentliche Aussetzer, Knackser und ähnliche Phänomene (Stand: November 2021); manche – selbst hochpreisige – Geräte, die noch im Laufe des Jahres 2021 verkauft wurden, sind vollständig inkompatibel zu AAC und lassen sich in einigen Fällen auch nicht updaten. Betroffen sind neben Satelliten- auch Kabelreceiver, die von den entsprechenden Kabelbetreibern – vor allem jenen, die das analoge UKW-Signal in ihrem Netz mittlerweile abgeschaltet haben – noch bis vor wenigen Monaten als UKW-Nachfolgegeräte an ihre Kunden vertrieben wurden.
Grund: Der Audio-Codec AAC ist im DVB-Standard zwar vorgesehen, für Gerätehersteller aus diversen Gründen (u.a. Lizenzgebühren) aber immer schon nur optional gewesen. Sprich: selbst 2021 durften und dürfen z.B. Kabelradios, die lediglich MP2 beherrschen, nicht aber AAC, als „DVB-C“-konform verkauft werden. Solche Geräte werden aber künftig beim ARD-Hörfunk stumm bleiben.
Ein weiteres, eventuell unterschätztes Problem sind die vielen (auch kleineren) oben bereits erwähnten Kabelnetzbetreiber (und ich spreche hier explizit nicht von Vodafone, Unity & Co.!), die ihre DVB-Umsetzer jetzt erneuern müssen. Dabei handelt es sich oft um lokal organisierte Vereine, die aber ganze Wohnanlagen („Gemeinschaftsantennenanlagen“) mit DVB-C und oft auch noch einem UKW-Signal im Kabel versorgen. Den Austausch der dafür nötigen (leider ziemlich teuren) sogenannten Kopfstellentechnik gegen DVB-S2- und AAC-taugliche Komponenten können sich viele kleine Betreiber (Vereine etc.) oft nicht leisten. Über DVB-C und UKW bleibt der ARD-Hörfunk in solchen Anlagen also vielerorts künftig stumm.
Privatsender, die weiterhin in MPEG-1 Audio Layer II (MP2) ausstrahlen, sind davon nicht betroffen. Hoffentlich verliert die ARD mit der Aktion also nicht am Ende viele Hörer an die Konkurrenz.
Eine interessante Quelle mit weiteren Infos zu den möglichen Auswirkungen der Abschaltung ist diese Seite (inklusive Petition, die die ARD zur Beibehaltung des alten Transponders bewegen sollte, mit – Stand Dezember 2021 – nur 800 von geplanten 10.000 Unterstützern aber wohl ihr Ziel grandios verfehlt hat).
Tatsächlich ist auch die Qualität der AAC-Übertragung nicht immer ebenbürtig, seltenst besser als das bewährte MP2 bei den extrem hohen Bitraten des alten Transponders. Mehrkanalton in AC3, der ebenfalls nach wie vor den De-Facto-Standard darstellt, weil er von allen (AV-)Receivern dekodiert und wiedergegeben werden kann, wird es bis auf eine Ausnahme (NDR Kultur) auf den neuen Transpondern ebenfalls nicht mehr geben. Einige Anstalten wie der Hessische Rundfunk werden mit ihren Kulturwellen künftig die Ausstrahlung von Surround-Programmen vollständig beenden (auch wenn auf der zugehörigen Website von hr2-kultur noch weiter munter damit geworben wird). Einige (z.B. BR-KLASSIK) versuchen, den AAC-Mehrkanalton-Standard zur Anwendung zu bringen, der von einigen Endgeräten zwar unterstützt wird, von einigen aber auch nicht. Im besten Fall transcodiert der DVB-S2-Receiver diesen Ton in ein kompatibles AC3-5.1-Signal und gibt es an den AV-Receiver weiter. Im schlechtesten Fall hört man bei den Surround-Sendungen gar nichts oder nur Mono-Ton.
Mein persönliches Fazit aus der Sache: Ich weiß einfach nicht, ob die ARD sich mit der Aktion tatsächlich einen Gefallen tut. Ein ASTRA-Transponder kostet viel Geld, das ist klar, doch durch die eigentlich bereits viel länger überfällige Abschaltung der SD-Übertragung diverser dritter Fernsehprogramme und geschicktes Umsortieren hätten sich grundsätzlich mehr Transponder einsparen lassen, als der eine, hochkompatible DVB-S-Hörfunktransponder. Mal ganz davon abgesehen, dass ich mir nicht vorstellen kann, dass SES ASTRA im Jahr 2021 noch in einer so guten Verhandlungsposition ist, dass die ARD nicht ohne Probleme den Preis signifikant hätte runterverhandeln können. Im Zeitalter des sterbenden Linear-TVs und auch der immer mehr aussterbenden SNG-Übertragungen werden die Satellitenbetreiber noch auf vielen freien Transponderkapazitäten sitzen bleiben, sodass jeder vernünftige Verhandler auf der anderen Seite eigentlich jeden von der ARD gebotenen Preis für den ollen Tp 93 nehmen dürfte statt einer Abschaltung.
Aber wie gesagt – das ist nur meine persönliche Meinung, da steck ich nicht drin. Ich werde dem Transponder 93 mit seinen exzellenten Audioqualitäten von bis zu 320 kbit/s MP2 jedenfalls definitiv die eine oder andere Träne nachweinen.
Immer wieder ein Quell der Freude: Die ARD Mediathek.
Lust auf einen Rant zu einem anderen Thema als Corona? You’re Welcome!
Immer wieder ein Quell der Freude: Die ARD Mediathek.
Liebe ARD, genauer gesagt, liebes ARD Online in Mainz!
Ja, ihr habt mega viel Arbeit in die ARD Mediathek gesteckt in den letzten drei Jahren. Es hat sich vieles verbessert. Allein, dass es jetzt nicht mehr drei verschiedene Mediatheken gibt (Das Erste Mediathek, ARD Mediathek, die Dritten Programme – mit Ausnahme des BR, der ja irgendwie immer noch eine Extrawurst brät) ist löblich. Die Metadaten, die Verschlagwortung, die Suchfunktion, das Design und die Technologie dahinter werden langsam besser.
Aber all das darf nicht darüber hinwegtäuschen, dass die ARD Mediathek leider immer noch abgrundtief schlecht und unzuverlässig ist! So! Jetzt ist es raus!
Lobt euch bitte nicht für ein Produkt, das zwar besser als ein nicht mehr tragbares Vorgängerprodukt aus den 2000ern ist, aber nach heutigen Maßstäben (YouTube, Netflix) einfach immer noch unfassbar lächerlich ist. Und einfach an so vielen Stellen kaputt, ohne jegliche erkennbare Besserung in den letzten Monaten! Besonders, wenn man sie intensiv nutzt oder dies zumindest beabsichtigt, fällt das an allen Ecken und Enden auf.
Sendungen wie Tatort oder auch Brennpunkt tauchen immer noch drei, vier, fünfmal auf (bei den Dritten und im Ersten, mit und ohne Gebärdensprache, Sendungen im „Ersten“ auch immer noch viel zu häufig zweimal – einmal als Sendemitschnitt vom Ersten, einmal ohne SAW-Logos direkt zugeliefert).
Die Qualität schwankt extrem, von Full HD (mehr ist scheinbar nicht vorgesehen) bis zu ruckelndem Klötzchenbrei.
Immer wieder bleibt die Navigation im Vollbildmodus sichtbar und blendet sich ums Verrecken nicht aus. Egal, wie wild man mit der Maus gestikuliert, den Vollbildmodus verlässt, wieder aktiviert (das ist dann bei mir so ein Punkt wo ich wegschalte).
Weiter: bei „Sendungen A-Z“ fehlt bei jedem dritten Laden die Hälfte der Sendungen unter einem bestimmten Buchstaben. Reload bringt nichts. Ups, das Sandmännchen bringt einen „404 Error“. Weiter gehts, probierst du halt das Video über einen anderen Weg zu finden. Ach, da. Hups, „Die MediaCollection konnte nicht validiert werden“ (WTF?!).
Videos sind erst „ab 01.10.2021, 20:15 verfügbar“, obwohl es längst Dezember ist. Am Fernseher via HbbTV sind wahllos Videos „leider nicht verfügbar“. Die Lautstärkeregelung mit den Systemtasten verhält sich unter Windows immer noch erratisch (einmal mit der Maus auf „Mute“ in der Mediathek geklickt, ist es unmöglich, mit der Windows-Mute-Taste auf der Tastatur wieder zu unmuten, denn die toggelt dann das Windows-Mute und das Mediatheks-Mute gegenläufig. Liebe Developer, hört her: Die Mediathek darf nicht auf diese Tasten reagieren, die sollen nur die Systemlautstärke steuern, schon zig mal gemeldet, was ist denn daran so schwer zu verstehen?!).
Die Navigation ist generell unübersichtlich, es ist nicht immer klar, in welchem View man sich befindet, und auch der „Zurück“-Pfeil links oben macht oft nicht das, was man erwartet. Wenn er überhaupt da ist.
Willkürlich wird bei einigen Sendungen ein Datum angezeigt, bei anderen nicht. Hier zum Beispiel nicht:
Auf der Suche nach einer tagesschau-Ausgabe von einem bestimmten Datum? Viel Spaß!
Eine sich über zwei Zeilen erstreckende Qualitätsauswahl (ich zitiere: „Automatische Qualität – Niedrige Qualität – Mittlere Qualität – Hohe Qualität – Sehr hohe Qualität – Full HD“ – euer Ernst? „Hohe Qualität – Sehr hohe Qualität – Full HD“? Wenn ihr so viele Qualitätsstufen habt, schreibt doch wenigstens einfach die Auflösung hin, wie bei YouTube, dann weiß man bescheid!) überfordert den Nutzer.
Bei Nutzung im Browser reißt der UX-Flow einfach immer irgendwo ab, weil die ganze Sache in einen Zustand gerät, wo einfach keine Thumbnails mehr laden, Sendungen fehlen, oder, oder. Da hat sich in den letzten 24 Monaten keinen Deut was gebessert!
It – is – a – mess!
Liebe Leute, ernsthaft! Es macht auch 2021 immer noch einfach keinen Spaß, Inhalte bei euch anzuschauen. Niemand von euren anvisierten „jungen Zielgruppen“ wird sich von euch von Instagram, YouTube & Co. freiwillig auf die ARD Mediathek „locken lassen“, so lange es da so, mit Verlaub, sch…recklich ist! Seht das mal ein und repariert in einem ersten Schritt einfach mal alles oben Genannte! Die meisten dieser Fehler sind seit Monaten bekannt!
Und ich wünschte, ich könnte was anderes sagen, denn ich bin ja auf eurer Seite.